Motivation
- Semi-supervised learning: embeddings
- Unsupervised learning of word-level or phrase-level stats
- E.g: Word embeddings, ELMo Vectors
- Supervised training using these word-level features
- ELMo Example:
- Question Answering: Add ELMo to modified BiDAF model
- Textual Entailment: Add ELMo to ESIM sequence model
- Coreference Resolution: Add ELMo to end-to-end span-based neural model
- ELMo Example:
- Unsupervised learning of word-level or phrase-level stats
ELMo: Different Models for Each Task
- Question Answering
- Textual Entailment
- Coreference Resolution

Generative Pre-Training (GPT)
- Single Model: Transformers
- Make longer-distance connections
- Faster training
- Unsupervised pre-training
- Similar objective as Word2Vec
- Predict context words
- Supervised fine-tuning
- Use pre-trained model
- Only swap the last layer
- Takeaways
- Apply one pre-trained model to many tasks
- BPE Tokens
- Pre-trained Transformers learn something, even with no supervision
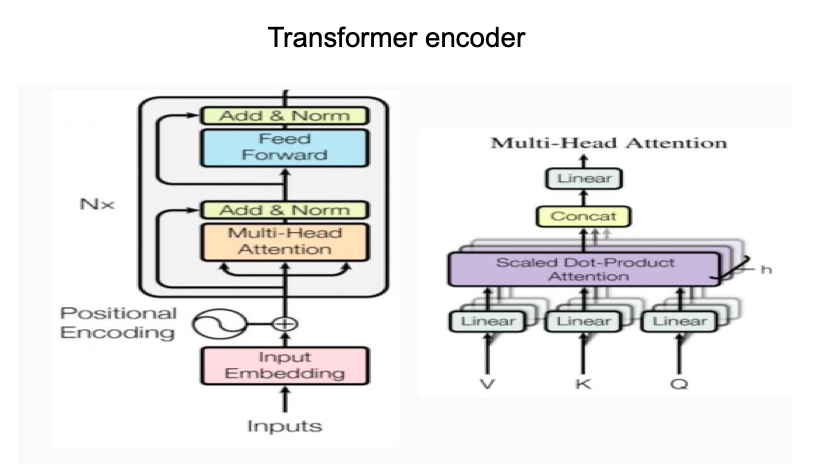
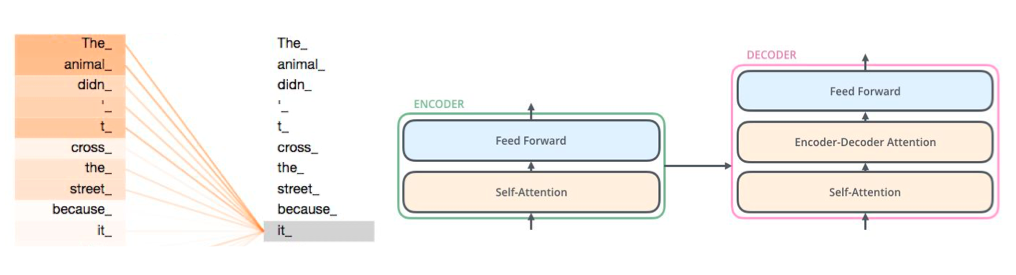
Transformer

Transformer Encoder and Decoder

Transformer is more efficient than LSTM because it lends itself to parallelization.
Self-Attention
Illustratede: Selfl-Attention
What do BERT, RoBERT, ALBERT, SpanBERT, DistilBERT, SesameeBERT, SemBERT, SciBERT, BioBERT, MobileBERT, TinyBERT and CamemBERT all have in common?
Self-attention. We are not only talking abuout architectures bearing the name “BERT” but, more correctly, Transformer-based architectures. Transformer-based architectures, which are primarily used in modelling language understanding tasks, eschew recurrence in neural networks and instead trust entirely on self-attention mechanisms to draw global dependencies between inputs and outputs.

SelfAttention in Detail
Multiplyiing $x_1$ by the $WQ$ weight matrix produces $q_1$, the “query” vector associated with that word. We end up creating a “query”, a “key”, and a “value” projection aof each word in the input sentence


Transformers
The Transformer - model architecture

GPT Framework
Generative Pre-trained Transformer (GPT) is an autoregressive language model
- Multi-layer Transformer decoder
- $h_0 = UW_e + W_p$
- $h_1 = transformerblock(h_{l-1}) ~\forall i \in [1, n]$
Unsuperised Pre-Training
- Similar objective as Word2Vec
- Given tokens u, maximize:
$L_1(U) = \sum_i logP(u_i|u_{i-k},…, u_{i-1};\Theta)$
$P(u) = softmax(h_nW^T_e)$ - k is context window size
- $h_nW^T_e$ is score for each word
- softmax gives probabiltity distribution
Supervised Fine-Tuning
- Keep the pre-trained Transformers
- Replace the final linear layer
- Datainputs x, label y
- Maximize
$L_2(C) = \sum_(x, y)logP(y|x^1, .., x^m)$
$P(y|x^1, .. x^m) = softmax(h^m_lW_y)$
$L_3(C) = L_2(C) + \lambda * L_1(C)$
Task Overviews
- Classification (e.g. sentiment analysis)
- Given a piece of text, is it positive or negative?
- Answers: “Yes”, “No”
- Answers: “Very positive”, “Positive”, “Neutral”, “Negative”, “Very negative”
- Entailment
- Given a premise p and a hypothesis h, does p imply h?
- Answers: “entailment”, “contradiction”, or “neutral”
- Similarity
- Are two sentences semantically equivalent?
- Answers: “Yes”, “No”
- Multiple Choice (e.g Story Cloze)
- Given a short story and two sentences, which is the sentence that ends the story?
- Given a passage and a question, and some multiple-choice answers, which is the answer?
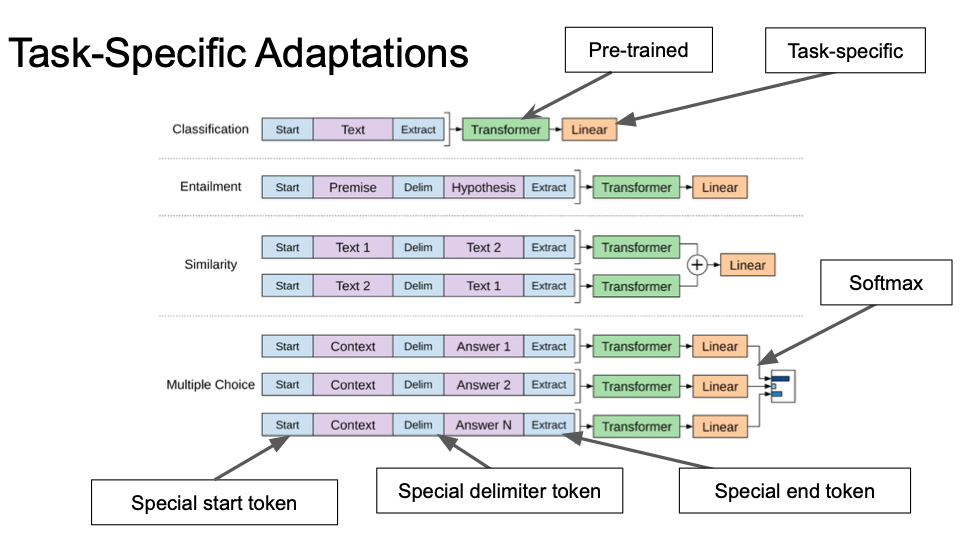
Task-Specific Adaptations
- Special start token
- Special delimiter token
- Special end token
- Softmax
- Task-specific
- Pre-trained
Experiments
- Books Corpus for unsupervised training
- About the same size as 1B Word Benchmark (used for ELMo)
- Preserves longer structure
- Model
- 12-layer transformer network
- Returns strong results on most tasks, especially question answering and commonsense reasoning
Takeaways
- Few new parameters for each supervised task
- One linear layer, plus delimiter embedding
- Transformers
- Allow long-term dependencies to be made
- Faster to train
- BPE Tokens
- Zero-shot Behavior
Binary Pair Encoding (BPE) Tokens
- Drawback of regular word tokens
- Other forms? (play vs playing)
- Compound words (overripe)
- Large vocab size
- Bgin with a vocabulary: Combine common character-pairs
- ‘A’ + ‘B -> ‘AB’
- Also, add an end-of-word symbol *
- Example: {‘low’, ‘lowest’, ‘newer’, ‘wider’}
- {‘low’, ‘lowest’, ‘newer’, ‘wider’} - Add {r, lo, low, er} to vocabulary - Before: l + o + w + e + r + _ - After: low + er_

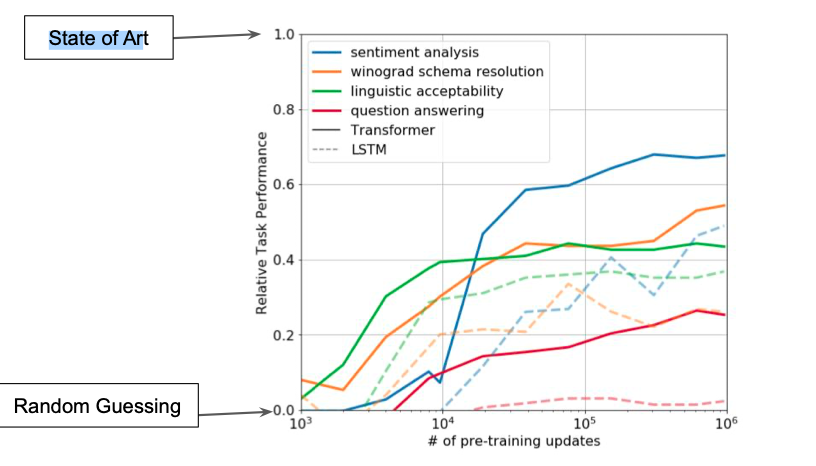
Zero-shot Behavior
- Use heuristics, rather than supervised trainning
- Use pre-trained model dircetly
- E.g: Question answering: Pick the answer the generative model assigns the highest probality to, conditioned on the document and question
Analysis: Zero-Shot Behavior
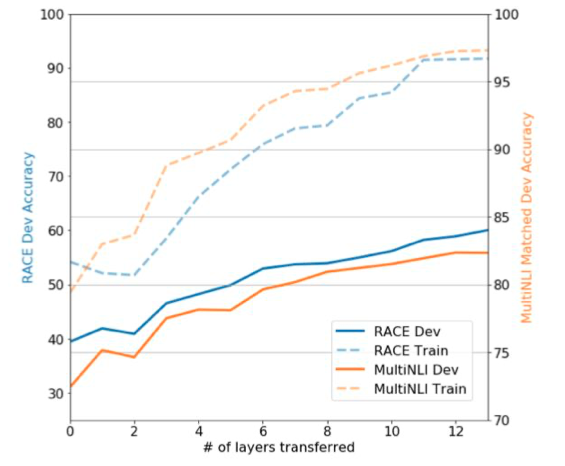
Analysis: Layer Transfer
Related Work
- Pre-trained LSTM
- (Dai et al.2015) and (Howard and Ruder 2018)
- Pre-train LSTM’s on sequence autoencoding, then apply to text classification
- Auxiliary unsupervised objectives
- Add an unsupervised goal to your objective
- E.g Ask your model to do context-prediction and text classification
- (Collobert and Westion 2008) and (Rei 2017)
- Add an unsupervised goal to your objective
Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding
Previous Work
- Language model pre-training has been used to improve many NLP tasks
- ELMo (Preters et al., 2018)
- OpenAI GPT (Redford et al., 2018)
- ULMFit (Howard and Rudder, 2018)
- Language model pre-training has been used to improve may NLP tasks
- Feature-based: include pre-trained representations as additional features (e.g., ELMo)
- Fine-tuning: introduce task-specific parameters and fine-tune the pre-trained parameters
Limitations of Revious Techniques
- Problem: Language models only use left context or right context, but language, understanding is bidirectional
- Why are LMs unidirectional?
- Reason: Words ccan “See themselves” in a bidirectional encoder.
Main Ideas
- Propose a new training objective so that a deep bidirectional transformer can be trained
- The masked language model
- Next Sentence Prediction
- Merits of BERT
- Just fine-tune BERT Model for specific tasks to achieve state-of-the-art performance
- BERT advances the state-of-the-art for eleven NLP tasks
Mask LM
- Solution: Mask out k% of the input words, and then predict the masked words
- We always use k = 15%
- Too little masking: Too expensive to train
- Too much masking: Not enough context
Mask LM (con’t)
- Problem: Mask token never seen at fine-tuning
- Solution: 15% of the words to predict, but don’t replace with {MASk} 100% of the time.
- 80% of the time, replace with {MASK}
- 10% of the time, replace random word
- 10% of the time, keep same
Next Sentence Prediction
- To learn relationships between sentences, predict whether Sentence B is actual sentence that proceeds Sentence A, or a random sentence E.g: Sentence A = “The man went to the store.” Sentence B = “Hebought a gallon of milk.” Label = IsNextSentence
Sentence A = “The man went to the store.” Sentence B = “Penguins are flightless” Label = NotNextSentence
Training Loss
- The training loss is the sum of the mean masked Language Model likelihood and the mean next sentence prediction likelihood
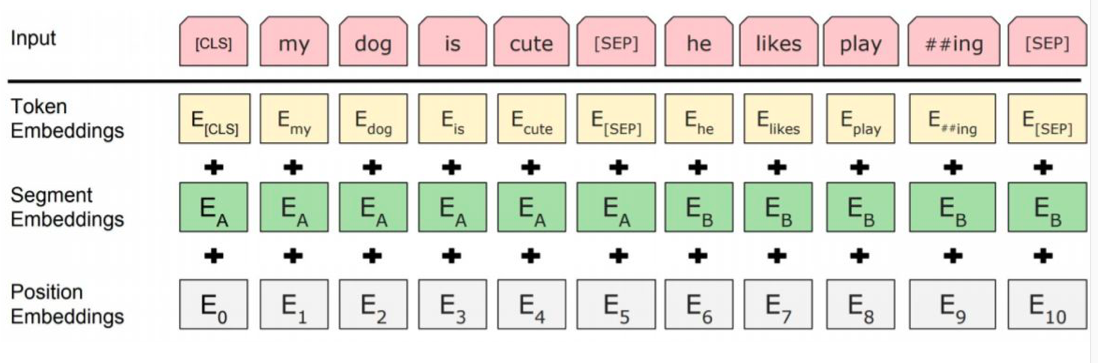
Input Representation
- Use 30.000 WordPiece vocabulary on input
- Each token is sum of three embeddings
Model Architecture
- Transformer encoder
- Bert (Ours)
- OpenAI GPT
- ELMo
- OpenAI GPT- ELMo.png)
Model Details
- Data: Wikipedia (2.5B words) + BookCorpus (80M words)
- Batch Size: 131.072 words (1024 sequences _ 128 length or 256 sequences _ 512 length)
- Training Time: 1M steps (~40 epochs)
- Optimizer: AdamW, 1e-4 learining reate, linear decay
- BERT-Base: 12-layer, 768-hidden, 12-head
- BERT-Large: 24-layer, 1024-hidden, 16-head
- Trained on 4x4 or 8x8 TPU slice for 4 days
Comparison of BERT and OpenAIGPT
| OpenAI GPT | BERT |
|---|---|
| Trained on BooksCorpus(800M) | TrainedonBooksCorpus (800M) + Wikipedia (2.5B) |
| Use sentence separater(SEP) and classifier token (CLS) only at fine-tuning time | BERT learns (SEP), (CLS) and sentence A/B embeddings during pre-training |
| Trained for 1M step with a batch-size of 32.000 words | Trained for 1M steps with a batch-size of 128.000 words |
| Use the same learning rate of 5e-5 for all fine tuing experiments | BERT choose a tas-specific learning rate wich preforms the best on the development set |
Fine-Tuning Procedure
- Pe-training
- Fine-Tuning
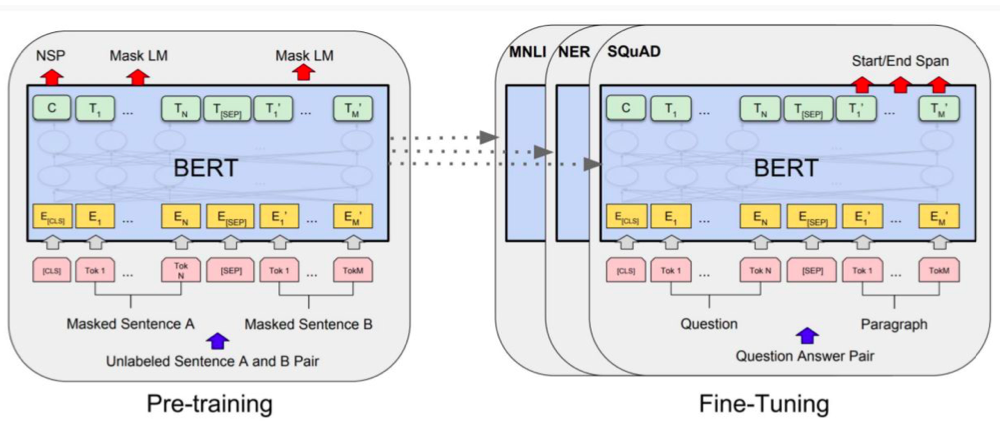
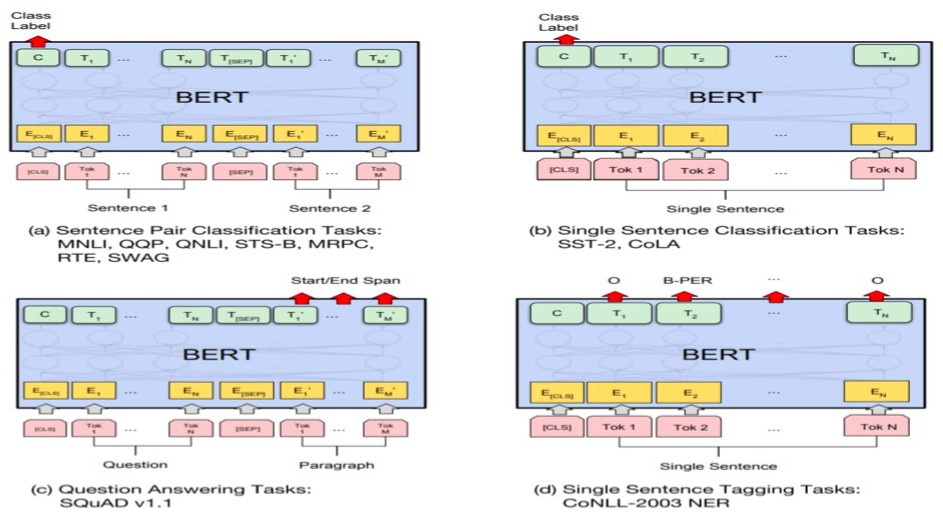
Fine-Tuning For Specific Tasks
a. Sentence Pair Classification Tasks: MNLI, QQP, QNLI, STS-B, MRPC, RTE, SWAG
b. Single Sentence Classification Tasks: SST-2, CoLA
c. Question Answering Tasks: SQuAD v1.1
d. Single Sentence Tagging Tasks: CoNLL-2003 NER
Conclusions
- Pre-trained language models are increasingly adopted in many NLP tasks
- Major contribution of this paper is to propose a deep bidirectional architecture from Transformer.
Pre-training and Fine-tuning
Sentence prediction
- NSP could hurt the MLM training objective
- Recommended reading: SpanBERT: Improving Pre-training by Representing and Predicting Spans
Fine-tuning vs Feature-based
- Howww ???
XLNET: Generalized Autoregressive Pre-training for Language Understanding
- XLNet Key Ideas: high-level comparison with BERT
- XLNet Backbone: Transformer-XL
- Pre-training Objectives: comparison with AR and BERT
- XLNet Design: permutation,masks, two-stream attention
- Results: XLNet outperform BERT on 20 tasks
Background
- Before: autoregressive (ex. ELMo, GPT) and autoencoding (ex. BERT) models are the two most successful pre-training objectives
- Both approaches have their own limitations
Autoregressive Models
Use context to predict the next word
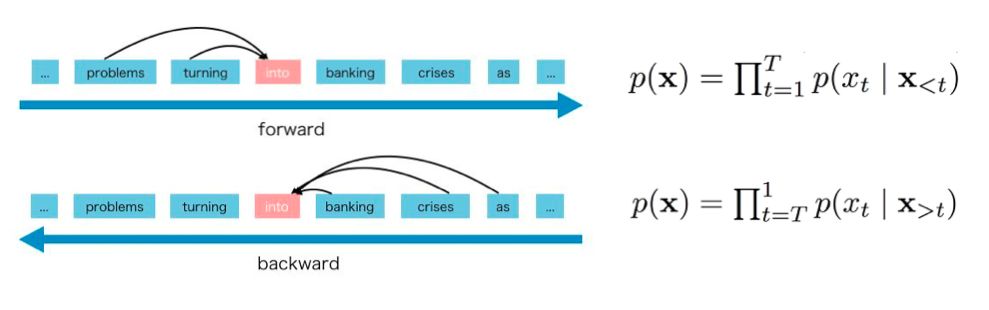 Only considers context in one direction
Only considers context in one direction
Autoencoding Models (BERT)
Note: previously a SOTA pretraining approach
.png) Fine-tuning discrepancy caused by {MASK} tokens (not in real data)
E.g:
Fine-tuning discrepancy caused by {MASK} tokens (not in real data)
E.g:
- Peter has a {MASK} that does not like {MASK}
- Assumes cat and yam are independent, which is wrong No joint pobability between masked entries
Two Notable Objectives for Language Pretraining
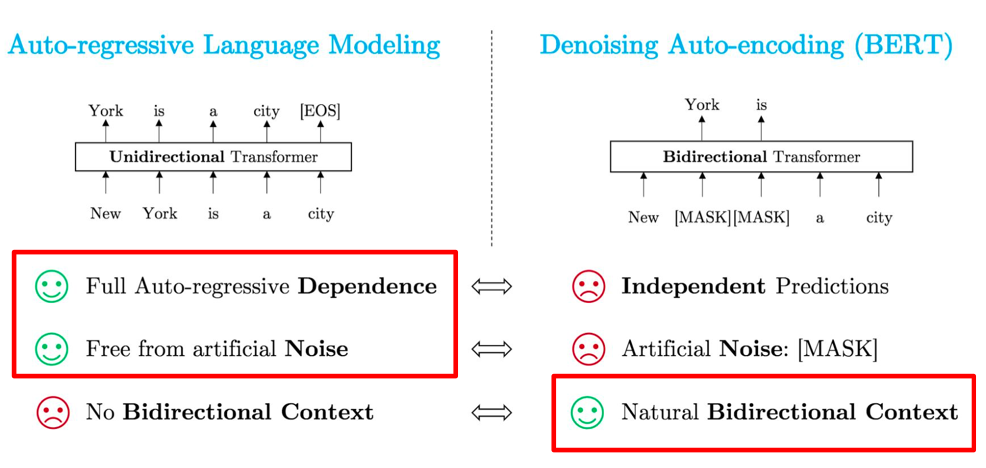
Auto-regressive Language Modeling
- Full Auto-regressive Dependence
- Free from artificial Noise
- No Bidirectional Context
Denosing Auto-encoding (BERT)
- Independent Predictions
- Artificial Noise: {MASK}
- Natural Bidirectional Context
XLNet Key Ideas
- Autoregressive: use context to predict the next word
-
Bidirectional context from permutation language modeling
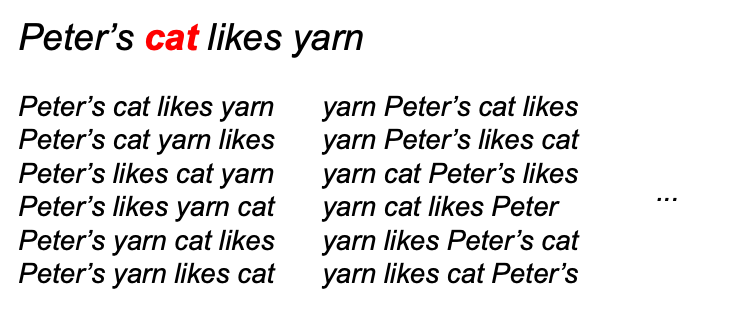
- Self-attention mechanisms, uses Transformer-XL backbone
Transformer-XL
XL is mean Extra Long
Increases context through segment-level recurrence and a novel positional encoding scheme
- Cache and reuse hidden state from the previous segment
- Allows variable-length context, great for capturing long-term dependencies
- Resolves the problem of context fragmentation
Before (no segment-level recurrence)
.png)
After segment-level recurrence
Increases context through segment-level recurrence and a novel positional encoding scheme
Need a way to keep positional inforamtion coherent when we reuse the states
- In the original Transformer: absolute position within a segment is used
- Need to encode relative position
Training objectives
Traditional AR models vs BERT vs XLNet
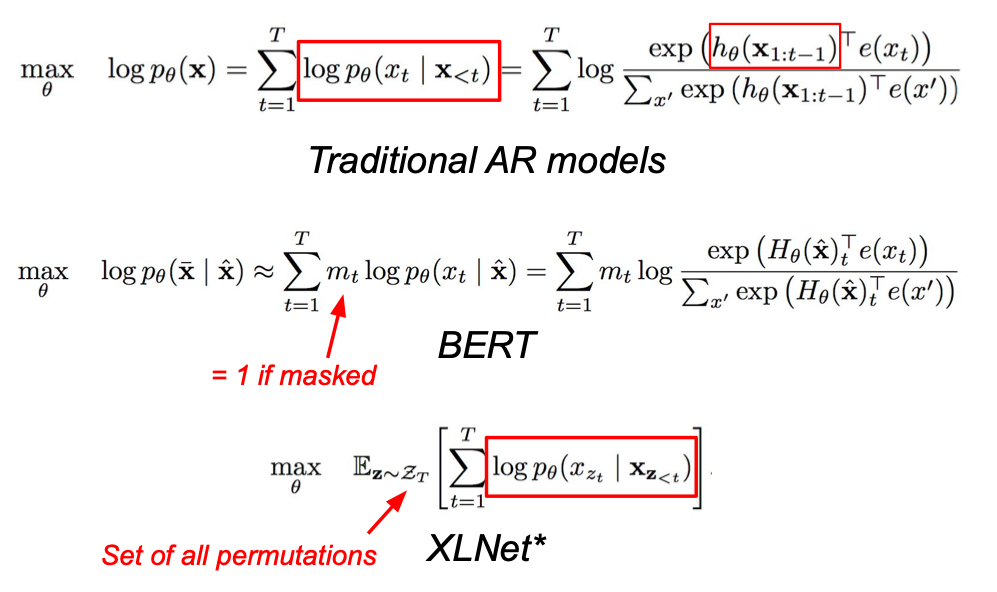
XLNet Design
Premutation
Premutation only on factorization order, not the orighinal sequence order
Context Depends on the Factorization Order
-
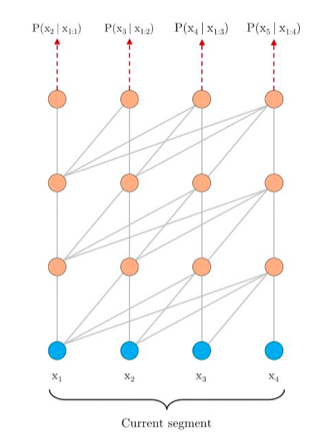
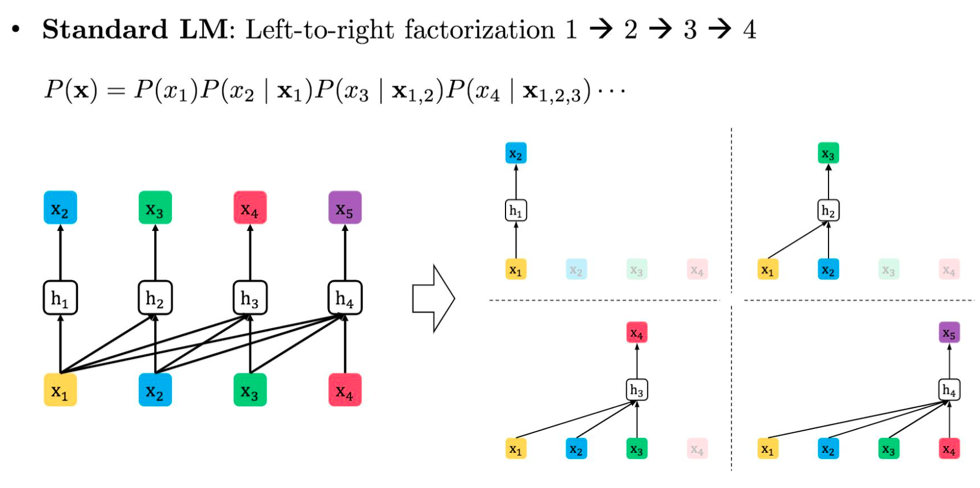
Standard LM: Left to right factorization 1 -> 2 -> 3 -> 4
\(P(x) = P(x_1)P(x_2|x_1)P(x_3|x_{1,2})P(x_4|x_{1,2,3})\)
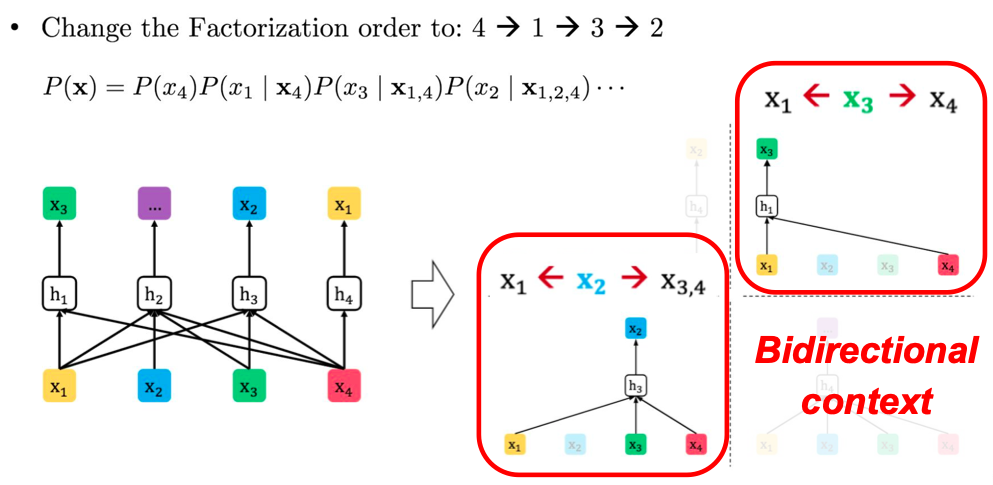
- Change the Factorization order to: 4 -> 1 -> 3 -> 2
\(P(x) = P(x_4)P(x_1|x_4) P(x_3|x_{1,4})P(x_2|x_{1,2,4})\)
Premutation Language Modeling - Given a sequence x of length T
- Uniformly sample a factorization order z from all possible premutations
- Maximize the premutated log-likelihood
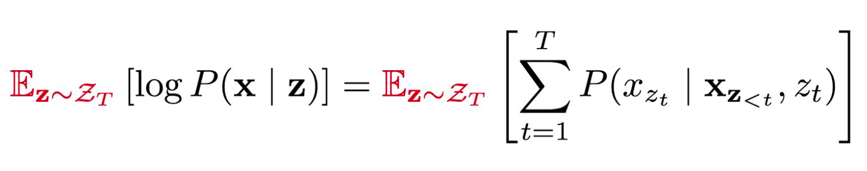
Attention masks
Attention masks provide the context for each prediction
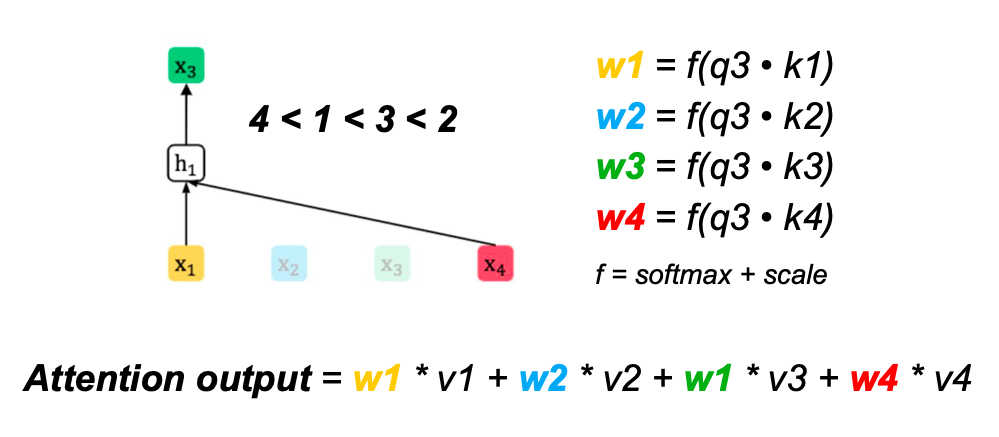
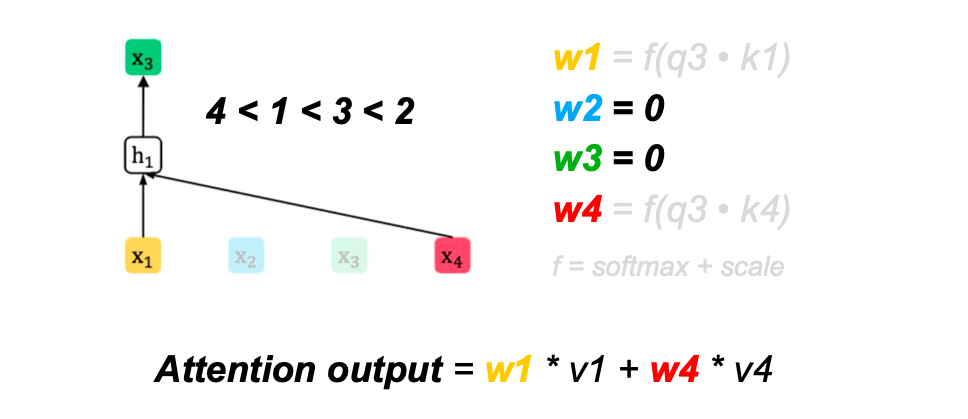
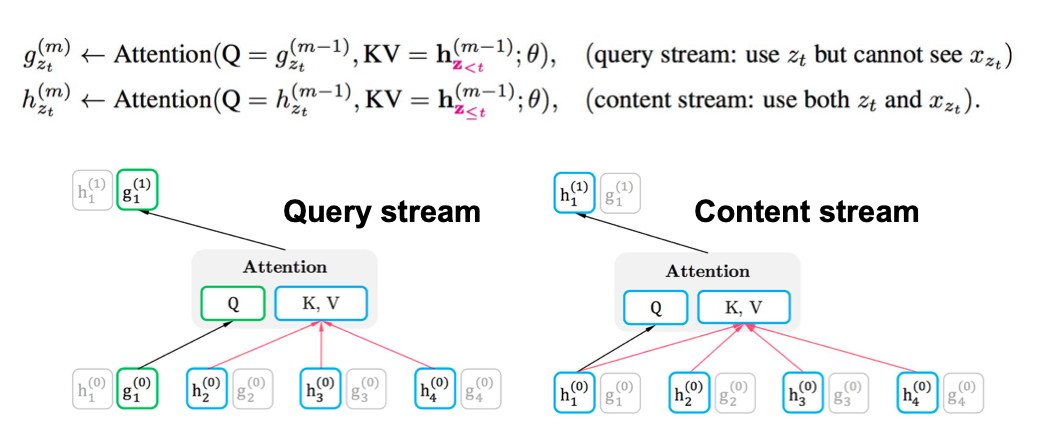
Two-stream self-attention
Two-stream self-attention allows prediction to be aware of target position
Standard AR Parameterization Fails
E.g:
z = apple was the eaten = \(p(x|apple, was, pos=0)\)
z = apple was eaten the = \(p(x|apple, was, pos=3)\)
Predicting the and eaten uses the same distribution
Fails to take account target position
Reparameterization
- Satandaard Softmax doeas Not work
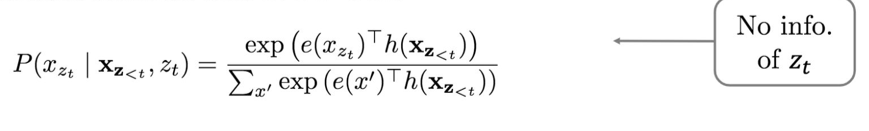
- Proposed solution: incorporate $z_t$ into hidden states
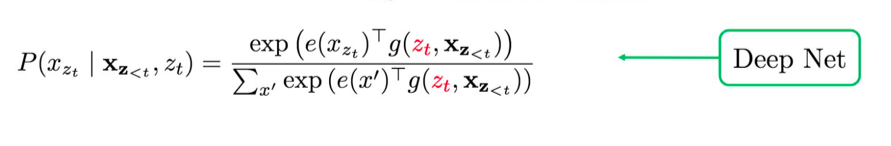 Implement this using two-stream architecture
Implement this using two-stream architecture
Target Position Aware Representation: $g(z_t, x_{z<t})$
Reuse the Idea of Attention
- Stand at the target position $z_t$
- Gather information from $x_{z<t}$

Contradiction: Predicting Self and Others
- Factorization order: 4 -> 1 -> 3 -> 2
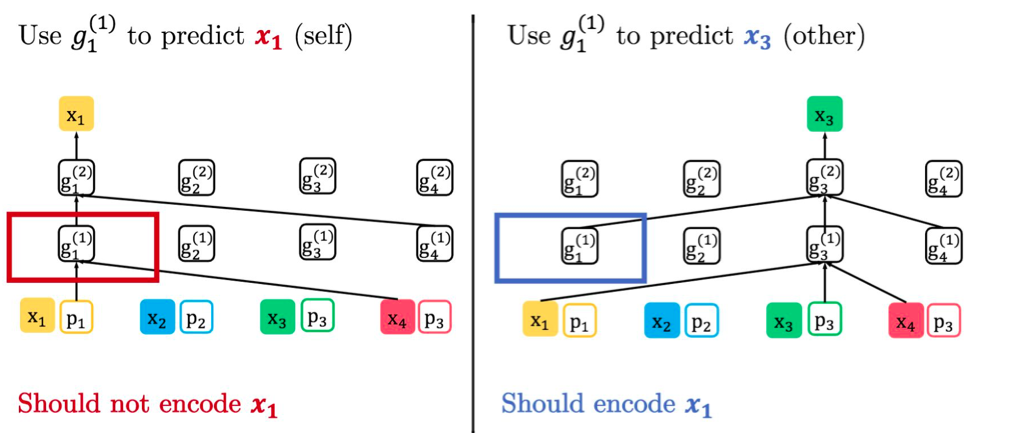
Two-Streeam Self-Attention
- Query stream: encodes target position information ($z_t$)
- Content stream encodes both context and the target word ($x_{z_t}$)
Partial prediction
Partial prediction: only predict 1/K tokens in each premutation
Motivation: reduce optimization difficulty from too little context
Split sequence into context words and target words, cut off at $c$
Only predict target words ($1/K$ of original sequence)
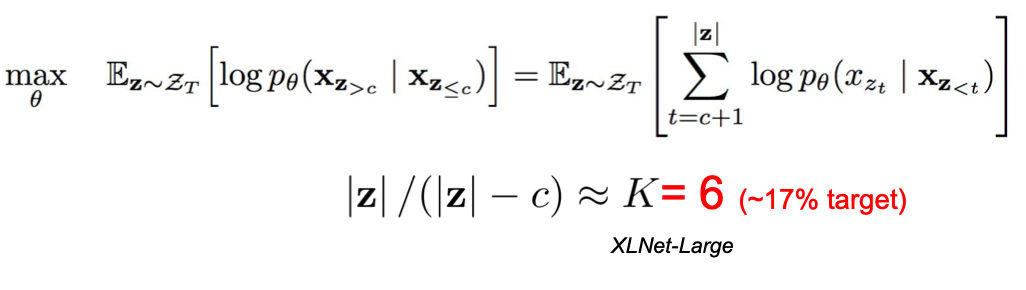
Example: Comparison with BERT
Input sentence: New York is a city, masked New and York
XLNet factorization order: {is, a, city, New, York}
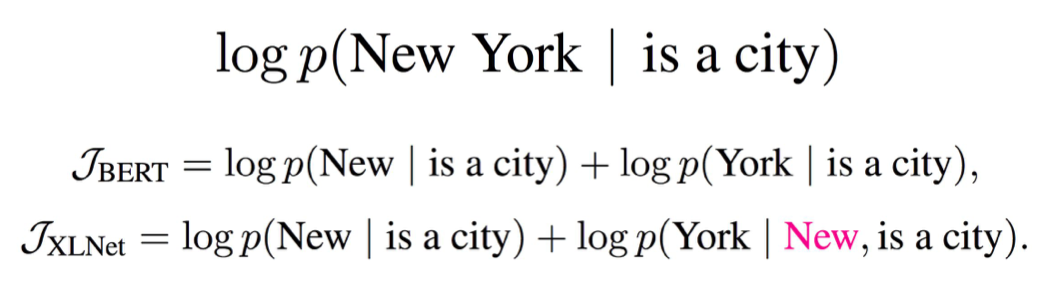
XLNet
XLNet is The Best pretrained model today
Given standard Flops

Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Transfer Text to Text Transformer : T5
Paper: https://arxiv.org/pdf/1910.10683.pdf