Overview
- Papers: OpenAI GPT/BERT
- (McCann et al, NIPS’2017) Learned in translation: contextualized word vectors
- (Peters et al, NAACL’2018) Deep contextuatualized word representations
Limitations of word2vec
- One vector for each word type
\(v(bank)=(-0.224, 0.130, -0.290, 0.276)\) - Polysemous words:
- mouse: .. a mouse controlling a computer system in 1968.
- mouse: .. a quiet animal like a mouse
- bank: … a bank can hold the investments in a custodial account ..
- bank: … as agriculture burgeons on the east bank, the river …
- Words don’t appear in isolation. The word use (eg. syntax and semantics) depends on its context. Why not learn the representations for each word in its context?
Contextualized word embeddings
Build a vectorr for each word conditioned on its context
= representation for each token is a function of the entire input sentence

Compute contextualk vector:
\[c_k = f(w_k|w_1, w_2, ..., w_n) \in R^d\] \[f(play|Elmo~and~Cookie~Monster~play~a~game) \neq f(play | he~Broadway~play~premiered~yesterday)\]Context Vectors (CoVe)
We transfer what is learned by the MT-LSTM to downstream tasks by treating the outputs of the MT-LSTM as context vectors. If w is a sequence of words and GloVe(w) the corresponding sequence of word vectors produced by the GloVe model
\[CoVe(w) = MT-LSTM(GloVe(w))\]Sequence to Sequence (seq2seq) and Attention
Paper: Sequence to Sequence Basics
The most popular sequence to sequence task is translation: usually from one natural language to another.
Sequence to Sequence basic
Input sequence $x_1, x_2, .. x_m$
Output sequence $y_1, y_2, …, y_n$

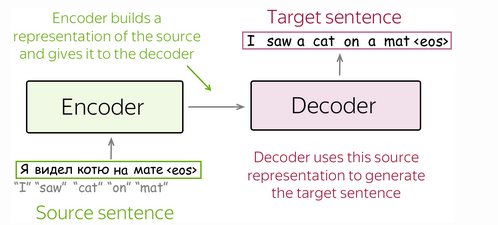
Encoder-Decoder Framework
Encoder-decoder is the standard modeling paradigm for seq2seq tasks. This framework consists of two components:
- Encoder - reads source sequence and produces its representation:
- Decode - uses source representation from the encoder to generate the target sequence
Conditional Language Models
Language Models:
\(P(y_1, y_2, ..., y_n = \prod{n}_{t=1}p(y_t|y_{<t})\)
Conditional Language Models:
\(P(y_1, y_2, ..., y_n = \prod{n}_{t=1}p(y_t|y_{<t})\)
Since the only difference from LMs is the presence of cource x, the modeling and training is very similar to language models. In particular, the high-level pipeline is as follows:
- feed source and previously generated target words into a network;
- get vector representation of context (both source and previous target) from the networds decoder;
- from this vector representation, predict a probability distribution for the next token.

The Simplest Model: Two RNNs for Encoder and Decoder

The simplest encoder-decoder model consists of two RNNs (LSTMs): one for the encode and another for the decoder. Encoder RNN reads the source sentence, and the final state is used as the initial state of the decoder RNN. The hope is that the final encoder state “encodes” all information about the source, and the decoder can generate the target sentence based on this vector.
ELMo
- Train a forward LSTM-based LM and a backward LSTM-based LM on some large corpus
- Use the hidden states of the LSTMs for each token to compute a vector representation of each word
ELMo != bidirectional LSTMs
- Essentially two LSTMs in different directions

How to use ELMo
- Plug ELMo into any NLP model: freeze all the LMs weights and change the input representation to: \([x_k; ELMo_{k}^{task}]\)
- Could also insert ELMo into higher laers (will discuss soon)
Evaluation
- SQuaAD: question answering
- SNLI: textual entailment
- SRL: semantic role labeling
- Coref: coreference resolution
- NER: named entity recognition
- SST-5: sentiment analysis
Bidirectional Encoder Representations form Transformer (Bert)
Document: illustrated-bert, BERT: Pre-training of DBTLU
BERT brought everythink together to build a bidirectional transformer-based language model using endcoders rather than decoders They emplayed masked language modeling. In other words, they hid 15% of the words and used their position information to infer them. Finally, they also mixed it up a littele bit to make the learning process more effective
Example: Sentence Classification The most straight-forward way to use BERT is to use it to classify a single piece of text. This model would book like this:

In fact, BERT developers created two main models:
- The BASE:
- Number of transformer blocks (L): 12
- Hidden layer size (H): 768
- Attention heads(A): 12
- The LARGE:
- Number of transformer blocks (L): 24
- Hidden layer size (H): 1024
- Attention heads (A): 16
I will be using the BASE model BERT’s architecture looks like this:

Each encoder block encapsulates a more sophisticated model architecture.
The special tokens that BERT authors used for fine-tuning and specific task training.
- {CLS}: The first token of every sequence. A classification token which is normally used in conjunction with a softmax layer for classification tasks. For anything else, it can be safely ignored.
- {SEP}: A sequence delimiter token which was used at pre-training for sequence-pair tasks (i.e. Next entence prediction). Must be used when sequence pair tasks are required. When a single sequence is used it is just appended at the end.
- {MASK}: Token used for masked words. Only used for pre-training.
The input format that BERT expects is illustrated below:

The input layer is simply the vector of the sequence tokens along with the special tokens. The “##ing” token in thae example above may raise some eyebrows so to clarify, BERT utilizes WordRiece for tokenization which in effect, splits token like “playing” to “play” and “##ing”. This is mainly to vover a wider spectrum of Out-Of-Vocabulary (OOV) words.
Token embeddings are the vocabulary IDs for each of the tokens. Sentence Embeddings is just a numeric class to distinguish between sentence A and B. Transformer positional embeddings indicate the position of each word in the sequence.
Source code: